


This article is longer than most. That's because it's more important than most. If you avoid these software mistakes when starting a new project, you will save yourself a lot of grief. And by grief, I mean "money."
My new client was playing the long game. They needed data for analysis.
Lots and lots of data. They had been saving customer data for two years,
waiting for the critical mass at which they could have their data science team
dive into it. I wasn't on this project, but I was doing some work on their
system when I happened to notice some warnings from their database that I was
all too familiar with: Data truncated for column ....
No, that wasn't an error; it was a warning. Many of you are familiar with that horror story: MySQL wasn't being run in STRICT or TRADITIONAL mode.. Further investigation revealed that the data being truncated was the key the client was using to link this valuable customer data together. It was impossible to reconstruct. Two years of valuable data had to be thrown away because the client didn't know how to configure MySQL.
This, and many other disasters, can be avoided by taking a little time up front to understand common errors on large projects.
The Database
I find it interesting that when I go into a shop running Oracle or MySQL, the database is usually a mess and there's lot of work to fix there. When I go into a shop running PostgreSQL, the database is usually fine. I can't prove this, but I suspect it's because people who really understand databases reach for PostgreSQL due to its obsession with data quality, while people who just use databases reach for MySQL because it's "easy" or Oracle because "the company said so."
As a further data point, when I hire people, there's a small technical test. I've given that test hundreds of times. It was three years before a single developer returned that test with a properly normalized database. There were no "gotchas" and the database itself only required five tables to be normalized correctly. Many of these were excellent developers with a decade or more of experience but nonetheless turned in sloppy databases. It was trivial to demonstrate potential data anomalies in their database. Most software developers don't understand databases.
By running a default configuration of MySQL, you can get invalid dates,
truncated data, NULL values for division by zero instead of an
error, and so on. MySQL and MariaDB have other issues, but this is the biggest
one. Every one of my clients who has used MySQL and tried to get themselves
into STRICT mode have found their software assumes sloppiness in the
data and can't run with a properly configured database.
Recommendation: if you must use MySQL, ensure you're using one of the recommended modes and have a competent DBA who understands database design and performance. Otherwise, if there's not strong requirement for choice of database, use PostgreSQL. I've heard DBAs complain that it takes more work to administer, but that's because motorcyles require more maintenance than bicycles, but they'll get you there faster.
Database Migrations
When dealing with new clients:
Me: "How do you update the database?"
Client: "Run this script. It searches through the SQL directory to find the latest SQL we checked in. It runs that in your database."
Me: "How do you back out the change if there's a problem?"
Client: "Uh, there's hardly ever a problem, but we fix it by hand."
And things go downhill from there. I frequently meet clients with insane database migration strategies. The "dump SQL in a directory" for people to apply is an annoyingly common strategy. There's no clear way to roll it back and, if you're using MySQL or Oracle, if it contains DDL changes, those aren't transaction safe, so they really should be in their own migration, but they're not.
A few clients have an in-house database migration strategy involving numbered migrations. It often looks like this:
...
213-up-add-index-on-address-state.sql
213-down-add-index-on-address-state.sql
214-up-add-customer-notes-table.sql
214-down-add-customer-notes-table.sql
215-up-add-sales-tax-sproc.sql
215-down-add-sales-tax-sproc.sql
That, at least, can allow devs to back out changes (but tricky if your DDL isn't transaction-safe), but it's amazing when you get to migration 215 and you have 30 developers, five of them need to make a datababase change an they're arguing over who gets number 216. Yes, I've seen this happen more than once.
With a naïve numbering strategy, you can't declare dependencies, you get numbering conflicts, you really can't "tag" a particular migration for deployment, and so on.
Or there are the migration strategies which require migrations to be written in a particular programming language. Those are often nice, but can't always leverage the strength of the database, often write very poor SQL, and make it hard for other teams not using the language to write migrations.
Recommendation: just use sqitch. It's well-tested, not tied to a particular framework or programming language, let's you write changes in native SQL, declare dependencies, tag changes, and so on.
Oh, and it's free and open source.
Time Zones
This one still surprises me, but many clients are storing datetimes in their database in "local time." Most of the time this means "not UTC." I'll just get the recommendation out of the way now.
Recommendation: whenever possible, store dates and times in the database in UTC.
Many shops started out small and many datetime tools report the local time because if you're in Portland, Oregon, you get confused when it's 1:30 PM but your time function says 8:30 or 9:30 PM.
But it's worse than confusion. I've seen many test suites fail twice a year ... right when DST starts and ends. That costs money!
Or here are some fun problems documented in the Perl DateTime module: Ambiguous and invalid times.
Ambiguous Local Times
Because of Daylight Saving Time, it is possible to specify a local time that is ambiguous. For example, in the US in 2003, the transition from to saving to standard time occurred on October 26, at 02:00:00 local time. The local clock changed from 01:59:59 (saving time) to 01:00:00 (standard time). This means that the hour from 01:00:00 through 01:59:59 actually occurs twice, though the UTC time continues to move forward.
Invalid Local Times
Another problem introduced by Daylight Saving Time is that certain local times just do not exist. For example, in the US in 2003, the transition from standard to saving time occurred on April 6, at the change to 2:00:00 local time. The local clock changes from 01:59:59 (standard time) to 03:00:00 (saving time). This means that there is no 02:00:00 through 02:59:59 on April 6!
Using UTC doesn't make all of your problems go away, but because UTC doesn't use DST, you'll never have invalid or ambiguous times.
Time zone issues seem rather abstract, but as your company grows, these problems become more severe. In particular, if you work with other companies, they will be very unhappy if you cut off their services an hour or two early simply because you got your time zones wrong. Or in one memorable case (NDA, sorry), a company printed up a bunch of schedules with all times an hour off because of this.
One of my clients in California tried to switch to UTC because they had gone worldwide and local time was causing them headaches. When they realized how much time and money it was going to cost, they switched to Mountain Standard Time (Arizona) because they don't use daylight savings time. My client simply accepted that all of their old dates would forever be an hour or two off.
NoSQL
One of my favorite interactions with a developer was in the Paris office of a client with legitimate "big data" needs. But their NoSQL solution (which I'm not going to name) was awful. It was slow, painful to query, but offered "eventual constistency." There was a different NoSQL solution that seemed like a better fit, including a much better query syntax. However, if you learn one thing as a consultant, let it be this: never assume your client is stupid. If you're wrong, your client gets angry. If you're right, your client gets angry.
I approached a senior dev who was there when the NoSQL decision was made, laid out my findings, and asked "what am I missing? I need help understanding your NoSQL choice."
He replied, "we misread the documentation."
I laughed; he didn't. He wasn't joking. This multi-million dollar business made a very expensive mistake that they couldn't easily back out of because they misread the documentation.
This is not unusual.
Many developers, me amongst them, get excited about new technologies. Either we want to explore new things (that's why we became developers!) or we want to pad our CVs. Neither of these is necessarily in the company's best interest. While I sometimes recommend NoSQL (I love Redis, for example), usually I urge caution. I've seen client after client reach for NoSQL without understanding it. Here's what you need to understand:
Before SQL, everything was NoSQL. That's why we have SQL.
If you're considering a NoSQL solution, here's a handy checklist for you:
- What problem are you trying to solve and do you really need to solve it?
- Why does your database not solve that? (NoSQL is a premature optimization if you don't have a database yet)
- How can you fix your database to solve that problem? (I'm amazed at how often this step is skipped)
- If your current developers can't answer the previous question, have you considered hiring an expert? (Often far less expensive than introducing a new technology)
- Why does a NoSQL solution solve this problem better?
- What type of NoSQL solution do you really need? Key/value? Column-oriented? Graph? And so on ...
- What limitations does your NoSQL solution have and how are you compensating for these?
Often when I see clients switching from SQL to NoSQL, I find they're trading a known set of problems for an unknown set of problems. How is that good for your business? NoSQL has its place, but given how many developers are don't understand databases, why do we magically assume they're going to understand the byzantine NoSQL solutions available?
Internationalization
If there is any chance that your software will ever need support for multiple languages, investigate building that support in from day one. One of my clients decide to expand from the US to the UK. Easy, right? Hmm, date formats are different. Currency symbol is different. And the subtle spelling differences were "labour"-intensive to fix. It cost them so much money relative to their meager earnings abroad that they canceled the project. They might revisit it someday, but not now.
When looking at internationalization (i18n-getting your code ready for localization) and localization (l10n-the actual translation and other changes necessary), even if you're not going to launch in another language, make a "secret" translation feature. Heck, make it Pig Latin if you want. Even if you get it wrong, it won't really matter because it's not for public consumption. Instead, render everything in Pig Latin and check the software (better, write a spider that can find untranslated strings). One you get over the initial hurdle, it will become second nature to not hard-code strings or date formats everywhere.
Recommendation: Start your i18n work from day one. Trying to change it later is very expensive.
The Takeaway
You may have noticed a pattern in the above. Early mistakes are often hard to notice until they turn into expensive mistakes.
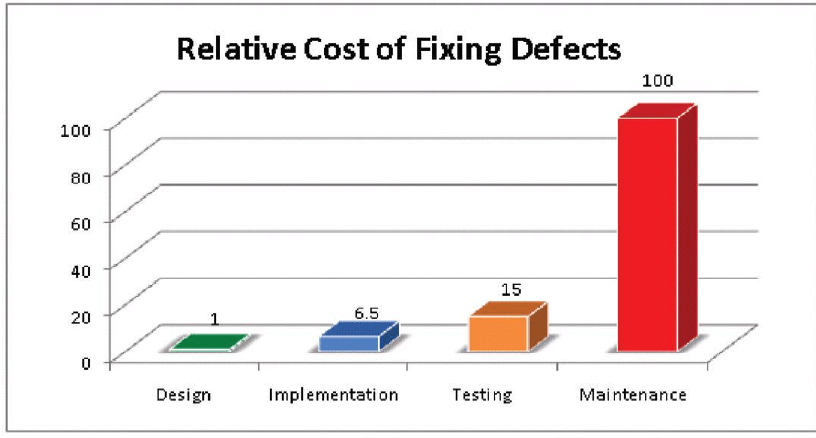
The sooner you catch bugs, the less money they cost to fix. When you're dealing with well-known categories of bugs, you have little excuse for them. For open source databases, I can't imagine starting a new project with MySQL instead of PostgreSQL. Of course you need to store times in UTC. Just say "no" to NoSQL until you can prove you need it.
Of the problems I mention above, them can all be fixed in the design phase but are often caught in the maintenance phase where it's literally two orders of magnitude more expensive to fix: every dollar you didn't spend up front becomes $100 dollars later, and that's not counting the money you lost because you didn't fix it.
I'm a huge fan of agile development, but agile shouldn't mean checking your brain at the door and it definitely shouldn't mean "don't think of the big picture." You'll save yourself a lot of money and grief if you take a little more time when you start a new project.
If you have any other "up front" design issues like those above, mention them in the comments below! Or better yet, tell me how many your project has made!